赋值语句、求值顺序和序列点
这个问题缘起网上著名的a=b=c的讨论,各种语言都有针对这个细节问题的讨论。
让我们来看一看这连续赋值在各种语言的行为,以及表象背后的语言设计本身。
y = x = {a : 1};
document.write(y.a + " " + x.a + "\n");
结果输出1和1,没有什么问题,如果不考虑y和x的作用域上可能存在的差别,上面的代码就相当于:
x = {a : 1};
y = x;
关于Javascript赋值语句的语义,可以参考http://deltamaster.is-programmer.com/posts/43687.html这篇文章。
而这个时候我又在网上发现了关于一种诡异代码的讨论:
x.n = x = {a : 2};
document.write(x.n + " " + x.a + "\n");
结果是undefined和2。这个时候如果我把这个语句拆开来写成两句,结果就不是这样:
x = {a : 2};
x.n = x;
document.write(x.n.a + " " + x.a + "\n");
这时候输出的结果是2和2。那么问题就来了,为什么这种情况下结果不同呢?
经过翻阅ECMAScript标准相关章节http://www.ecma-international.org/ecma-262/5.1/#sec-11.13,找到了蛛丝马迹。根据标准规定,对于赋值语句,总是先对lhs求值,再对rhs求值,然后PutValue。然后来看看求值顺序对结果的影响,我们一步一步来分析上面这条语句。
假设执行语句之前,x是一个空对象。第一步,首先对x.n进行求值,x没有属性n,那么为x添加属性n,左值的求值结果就是对刚才添加的属性n的引用。
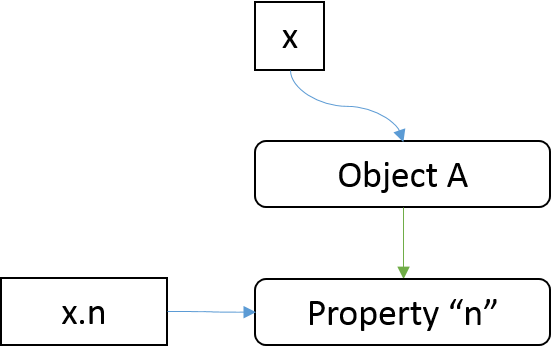
上面图中蓝色箭头表示引用关系。
第二步对右值进行求值,右值是x = {n : 2}。递归向下,先对左值求值,得到x,按照上图的话,应该也是引用Object A,然后对右值{a : 2}求值,得到Object B,接着PutValue将改变x的引用目标到Object B,赋值表达式x = {n : 2}返回Object B。
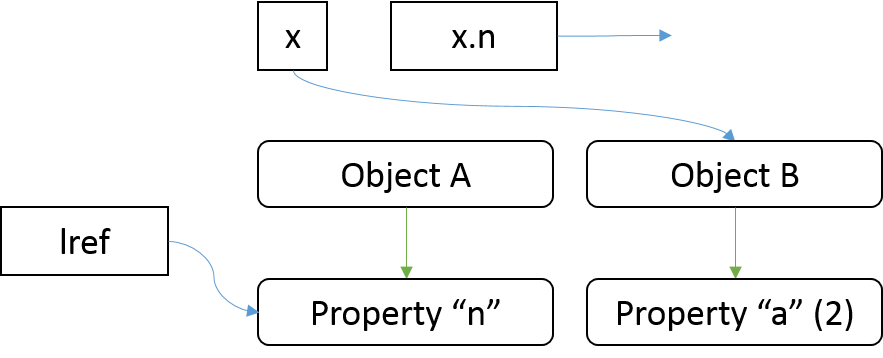
这个时候x和Object A已经解绑,那么相应的x.n也已经和Object A无关了,x.n的指向与刚才第一步求值得到的引用也没有了联系,而Object B这时候没有属性n,所以x.n这个时候是undefined。
第三步,PutValue将lref指向Object B。不过这个时候lref指向的属于Object A的属性n,已经没有被其他资源指向了,Object A的属性n也不再是x的属性n。
这样整个赋值过程就完成了,得到了x.n为undefined的结果。
让我们再来看看用C++尝试做类似的事情会是什么结果(下面的代码请使用支持C++11语法的编译器编译):
#include <iostream>
class A;
class A
{
public:
A* n = nullptr;
int a = 0;
};
int main()
{
A o;
o.a = 2;
A x;
x.n = &(x = o);
std::cout << x.n->a << std::endl;
return 0;
}
输出的结果是2。不过,这时候编译器给出了警告:main.cpp|18|warning: operation on 'x' may be undefined [-Wsequence-point]|。
这里面有两个问题。第一,C++的赋值语句返回的是左值,而其他许多语言(包括C语言,还有上面提到的Javascript)返回的是右值。因此上面的代码x.n = &(x = o)在C语言中是无法通过编译的,因为取地址运算的操作数必须是左值。第二,C、C++有序列点的概念,在两个序列点之间,如果发生多次副作用,那么这些副作用发生的顺序是不确定的(可以自行搜索关于“序列点”和“副作用”),只是在上面的这个实验中,x = o的副作用先发生了。
不同程序语言中引用、参数的引用传递及赋值运算符的语义
问题缘起一位同学在技术聚会上提出的关于Java参数传递方式的讨论。
public class HelloWorld{
public void f1(A a)
{
a.x = 5;
}
public void f2(A a)
{
a = new A();
a.x = 10;
}
public static void main(String []args)
{
HelloWorld o = new HelloWorld();
A a = new A();
o.f1(a);
System.out.println(a.x);
o.f2(a);
System.out.println(a.x);
}
}
上面给出了一段简单的Java程序,问程序的输出结果是什么。
我作为一名C++程序员,理所当然地觉得既然Java对于对象的参数传递方式是引用传递,那么就应该像C++一样,函数内的局部参数a不管被赋予了什么值,都始终应该等同于调用处的a,那么结果就应该是5和10了。不过事实证明我还是太年轻了,正确的结果应该是5和5。
要解决这个问题,我们得从引用、参数的引用传递以及赋值运算符的语义说起。于是回家之后我用了许多不同的语言进行试验,并尝试总结一些语言设计的观点。
在C中,赋值语句的含义是用rhs的值代替lhs的值,求值以后rhs与lhs除了在值上相同,没有任何关系。参数传递的时候也是类似,将实参的求值结果来构造函数的形参,形参值的改变也无法影响到实参。使用指针的方式传递参数(本质还是值传递)的话,对于指针所指向的资源的修改则是双方都可见的,不过如果函数改变了指针本身的值,也是不会影响到实参的。
在C++中新增加了引用的概念(相比C),从语义上讲,C++的引用就是别名,如果b是a的引用,那么b在它的生命周期内就永远代表a,任何对于b的操作完全等同于对于a的操作。不能改变引用目标,引用初始化时也必须指向一个有效的目标。所以函数参数如果使用引用传递,则对于形参的一切修改都等同于对实参的操作。
#include <iostream>
class A
{
public:
int x = 0;
};
void f1(A& a)
{
a.x = 5;
}
void f2(A& a)
{
a = *(new A); // memory leak
a.x = 10;
}
void f3(A* a)
{
a->x = 5;
}
void f4(A* a)
{
a = new A; // memory leak
a->x = 10;
}
int main()
{
A a;
f1(a);
std::cout << a.x << std::endl; // 5
f2(a);
std::cout << a.x << std::endl; // 10
A b;
f3(&b);
std::cout << b.x << std::endl; // 5
f4(&b);
std::cout << b.x << std::endl; // 5
return 0;
}
上面这段简单的C++程序有一些内存泄露,不过为了说明问题方便,请暂时不要在意这些细节。
程序中f1和f2为引用传递,f3和f4为指针传递,所做的事情与上面Java程序想要做的类似。所有函数的执行结果都写在了调用行后面的注释,根据上面对C++指针传递和引用传递的语义说明,结果都是意料之中的。
在这里指针传递的方式结果与Java是相同的。由此,在Java的参数传递的语义,类似于C的指针传递。因此Java即不支持对于对象的值传递,也不支持类似C++的引用传递。要模拟值传递,必须使用clone方法。
所以,Java的赋值运算符和参数传递语义都与C/C++不同。在Java中,赋值运算符的语义是,令lhs引用rhs所引用的资源;相应的,参数传递则是令形参引用实参所引用的资源。在顶上的Java程序的f2中,我将新建的对象赋值给形参a,则实际上令形参a指向了新建的对象,此时形参a和实参a的指向就不同了,而形参a原先指向的资源,引用计数减少了1,此时还有实参a指向它,等实参a的生命周期结束,这个资源没有其他人指向的时候,就可以自动被GC回收。
许多其他语言在这个问题上的处理与Java相同。
Javascript:
function f1(o)
{
o.x = 5;
}
function f2(o)
{
o = {x : 0};
o.x = 10;
}
var a = {x : 0};
f1(a);
document.write(a.x + "\n"); // 5
f2(a);
document.write(a.x + "\n"); // 5
PHP:
class A
{
public $x = 0;
}
function f1($a)
{
$a->x = 5;
}
function f2($a)
{
$a = new A();
$a->x = 10;
}
$a = new A();
f1($a);
echo "{$a->x}\n"; // 5
f2($a);
echo "{$a->x}\n"; // 5
Java、Javascript、PHP为什么不实现类似C++的引用?Java中的赋值运算符和参数传递,只有一种语法,如果选择C++引用的语义,那么就要丢失指针语义所带来的灵活性(指针的表达能力要强于引用);而如果引入其他语法规则,那么又需要重新引进指针概念。
而PHP恰恰提供了令一种参数传递的语法和赋值语法(=&),实现与C++功能相同的引用。
class A
{
public $x = 0;
}
function f1(&$a)
{
$a->x = 5;
}
function f2(&$a)
{
$a = new A();
$a->x = 10;
}
$a = new A();
f1($a);
echo "{$a->x}\n"; // 5
f2($a);
echo "{$a->x}\n"; // 10
所以,无论语言设计的细节是怎样,在赋值运算符和参数传递的语义上,始终可以参照C++的值传递、指针传递和引用传递来进行比较。
C++构造自动推导模板类型的function adaptor(STL Function Adaptor)
继续前一篇文章http://deltamaster.is-programmer.com/posts/41833.html关于构造function adaptor的话题。
template <typename operation>
operation derivative_functor(operation f, typename operation::argument_type dx)
{
typedef typename operation::argument_type T;
return [=](T x)->T {
return (f(x + dx) - f(x)) / dx;
};
}
这是前一篇文章最后构造的function adaptor。回忆一下,尽管我们不再需要在调用时指定lambda表达式的参数类型T,但是我们仍然需要指定operation的类型。从C++语法上讲,函数模板的调用应该是支持类型推导的,也就是说,如果调用derivative_functor的时候,没有指定operation的类型,C++编译时也会自动推导。可惜这种情况下自动推导的结果是错误的,以至于无法通过编译。
再看一下调用语句。
typedef function<double (double)> operation; cout << derivative_functor<operation>(my_sqr_functor<double>(), 0.000001)(5) << endl;
在这里我们给出的参数是my_sqr_functor<double>(),那么经过自动推导得到的operation类型就是my_sqr_functor<double>,尽管这个lambda表达式和my_sqr_functor<double>都分别兼容于类型function<double (double)>,但是它们两者之间没有继承关系,因此难以完成转换。
为了解决这个问题,我们就要避免出现这种不兼容的类型转换,只管的解决办法就是,令这个adaptor返回另一种类型的对象(而不是lambda表达式),这种对象的类型与operation指定的类型类似,并且同样可以像函数一样使用,兼容function<T (T)>类型。到这里我们必须要放弃lambda表达式,而用functor来模拟这个lambda表达式的行为了。
首先刚才说到,operation的类型和adaptor的返回类型有共性,下面让我们来构造这个共性的部分。
template<typename Arg, typename Result>
class my_unary_function
{
public:
typedef Arg argument_type;
typedef Result result_type;
private:
virtual Result operator()(Arg arg) = 0;
};
这两者都可以当做一元函数来使用,并且我们用typedef定义了argument_type和result_type了,关于这个typedef的使用前一篇已经有一些说明。
template<typename T>
class my_sqr_functor_derived : public my_unary_function<T, T>
{
public:
T operator()(T x)
{
return (x * x);
}
};
这个求平方的functor应该继承自这个my_unary_function,因为它“是”一个一元函数,这个继承关系会将父类的typedef一并继承下来。子类的T的实际类型会被代入父类my_unary_function的Arg和Result,成为自己的argument_type和result_type。
接下来就是重点的adaptor本身的改造了。
template <typename operation>
class derivative_functor_derived
: public my_unary_function<typename operation::argument_type, typename operation::result_type>
{
private:
operation op;
typename operation::argument_type dx;
public:
derivative_functor_derived(operation f, typename operation::argument_type x)
: op(f), dx(x) {}
typename operation::result_type operator()(typename operation::argument_type x)
{
return (op(x + dx) - op(x)) / dx;
}
};
首先这个adaptor现在是一个对象,它也“是”一个一元函数,因此同理,也继承自my_unary_function,并且指定恰当的模板参数。两个private对象,op和dx,就是先前lambda表达式中,从函数scope中传递下来的f和dx,我们在构造这个对象的时候,通过构造函数,将我们指定的op和dx保存到本对象的数据成员中,在括号运算符重载函数中,就可以使用op和dx了。至此,我们的adaptor是一个具有一元函数性质的对象,可以直接使用,而避免了不兼容类型的转换。
等一下!C++的语法不支持类模板的类型推导,这意味着我们调用这个构造函数的时候还是必须要指定的,像下面这样。
cout << derivative_functor_derived<my_sqr_functor_derived<double> >(my_sqr_functor_derived<double>(), 0.000001)(5) << endl;
我们刚才消除不兼容的类型转换,是为了省去模板参数的指定!别担心,注意到现在模板参数和传递的参数类型已经一致了吗?那现在我们只需要一个wrapper函数来帮助我们完成心愿。
template <typename operation>
derivative_functor_derived<operation> derivative_functor_derived_wrapper(operation f, typename operation::argument_type dx)
{
return derivative_functor_derived<operation>(f, dx);
}
这个函数所做的唯一的事情,就是调用了derivative_functor_derived的构造函数,不过因为这是一个函数模板,根据我们传递的f参数类型,就可以自动推导正确的operation类型了!
cout << derivative_functor_derived_wrapper(my_sqr_functor_derived<double>(), 0.000001)(5) << endl;
这里就是最终形式了。回想上一篇开头的STL Function Adaptor调用,看看是不是有些类似呢?
cout << count_if(v.begin(), v.end(), bind2nd(less<int>(), 12)) << endl;
我们的derivative_functor_derived_wrapper和STL函数模板bind2nd的行为完全一致。这就是STL Function Adaptor的实现原理。
至此,我们了解了STL Function Adaptor的设计思想和实现,并且能够使用functor来模拟一些lambda表达式的行为。
C++使用Lambda表达式做function adaptor
我们往往有许多现成的函数(或者是具有函数行为的对象),有些时候,我们希望通过改造这些函数来生成新的函数来为我们所用。
int myArr[] = {1, 1, 2, 3, 5, 8, 13, 21};
vector<int> v(myArr, myArr + sizeof(myArr) / sizeof(int));
cout << count_if(v.begin(), v.end(), bind2nd(less<int>(), 12)) << endl;
这段代码中less<int>()是临时functor对象,而bind2nd负责将这个接受两个参数比较他们大小的函数,将第二个参数绑定为12,改造成接受一个参数的functor,就可以被count_if所使用了。这段忙代码帮忙数出vector中小于12的项的数量。
我曾经在博客中写过利用Javascript闭包来实现的改造器。
function derivative(f, dx) {
return function (x) {
return (f(x + dx) - f(x)) / dx;
};
}
var result = derivative(function(x) {
return x * x;
}, 0.000001)(5);
这个derivative是一个改造器,接受参数是一个函数f,返回其导函数。具体解释请参考http://deltamaster.is-programmer.com/posts/28768.html。
下面我们要用C++的Lambda表达式来实现类似功能。
现有一个非常简单的函数,求x的平方,和上面Javascript中的例子相同。
double my_sqr(double x)
{
return (x * x);
}
下面我们写一个改造器。
function<double (double)> derivative_simple(function<double (double)> f, double dx)
{
return [=](double x)->double {
return (f(x + dx) - f(x)) / dx;
};
}
这个改造器是一个函数,接受的第一个参数是一个函数指针,或者其他具有函数行为的对象,这种对象作为函数使用的时候,接受一个double类型的参数,返回double类型。这个改造器的返回类型和它的第一个参数类型相同。
在我们返回的Lambda表达式中,我们从改造器的scope把f和dx都以值传递方式传递进来。这个Lambda表达式根据输入参数x,求出这一点的导数值。
然后我们调用它,并接着直接调用其返回的Lambda表达式,得到x=5这一点的导数值。如我们所愿,我们看到了10(微积分还没有忘光吧)。
cout << derivative_simple(my_sqr, 0.000001)(5) << endl;
不过有一点不够理想的是,这个改造器的适用范围太狭窄了,如果我需要求导的函数接受的不是double类型的参数,而是Stone类型(假设这种神奇的Stone能进行数值计算),我们就要再写另一个差不多的改造器。这里你应该差不多想到了,我们可以用模板来实现。
template <typename operation, typename T>
operation derivative_any(operation f, T dx)
{
return [=](T x)->T {
return (f(x + dx) - f(x)) / dx;
};
}
大家可以比较这里的operation和T出现的位置,和上面的例子比较一下。然后我们调用它。
typedef function<double (double)> operation; cout << derivative_any<operation, double>(my_sqr, 0.000001)(5) << endl;
我们在调用之前用typedef做了一个类型声明,简化下面调用语句的书写。这次调用的效果还是一样的。但是如果将来真的要把Stone传进来,我们只要将operation指定为function<Stone (Stone)>,将T指定为Stone就可以了。
到这里就有一个小问题了,因为其实operation里的参数和返回类型,应该和T指定的类型总是相同的。按照上面的写法,淘气的程序猿完全可以指定不同类型,而造成不必要的错误。在编译时期发现错误还好,如果是发生了非预期的隐式类型转换而造成运行时错误,就很难发现了。
这样就要求我们能够在operation里携带一些类型信息,再将这个类型信息在改造器中取出,取代现在T的位置。不过一个普通的函数没有办法隐含这样的信息,于是我们需要把这个求平方的函数本身变成一个functor,以便保存额外的类型信息。
template<typename T>
class my_sqr_functor
{
public:
typedef T argument_type;
T operator()(T x)
{
return (x * x);
}
};
在这里我们用typedef来把类模板参数T定义为argument_type类型。想象一下,当这个模板被展开的时候,T被各种不同的类型替换,比如double,这个时候我们用typedef,将double在类的范围内定义为了argument_type。这样,我们在这个类外也总是能够通过对象的argument_type来获得当初指定给T的类型。
下面修改我们的改造器。
template <typename operation>
operation derivative_functor(operation f, typename operation::argument_type dx)
{
typedef typename operation::argument_type T;
return [=](T x)->T {
return (f(x + dx) - f(x)) / dx;
};
}
改造器也相应升级了,我们在这里不需要再指定模板参数T了,而是用typename operation::argument_type来代替。下面再将它定义成T纯粹是为了书写方便。改造器的功能基本没有变化。然后我们调用它。
typedef function<double (double)> operation; cout << derivative_functor<operation>(my_sqr_functor<double>(), 0.000001)(5) << endl;
调用方法和上面稍有不同的,一方面我们不再能够指定那个模板参数T,另一方面my_sqr_functor<double>不再是一个函数,而是一个模板类,直接在后面加上括号调用其默认构造函数构造了一个临时对象,这种写法和最开头看到的less<int>()是同样的含义。
C++对于this指针使用placement new的隐患
我们知道使用placement new可以直接在现有的指针上构造对象,而不是先分配内存,再构造对象。这种技术经常被用在内存池管理中来优化内存管理效率。
有些情况下,我们希望能够让类的一个构造函数去调用另一个构造函数帮助我们完成工作,实现某种程度上的代码重用。比如下面这个例子。
class Factory
{
private:
Widget widget;
public:
Factory()
{
new (this) Factory("factory");
}
Factory(const char *name) : widget(name) { /* something else useful */ }
};
当Factory的默认构造函数被调用的时候,我们用Factory的默认名字“factory”去调用它自己的那个接受一个参数的构造函数,因为我们让placement new在自己(this)身上进行就地构造。不幸的是,这个例子里构造函数和析构函数没有配对调用的。
当调用者调用默认构造函数的时候,在函数体任何代码执行之前,所有Factory的子对象,也就是widget的默认构造函数Widget()被调用了。然后Factory决定再次调用自己带有一个参数的构造函数版本来完成构造,这个时候widget将再次被构造。最后当这个Factory的对象被析构时,相应的会调用一次widget的析构函数来销毁widget。
假设我们构造的这个Factory对象叫f。如果在Widget的默认构造函数中申请并占有资源,那么在f.widget没有被析构的情况下再次调用构造函数,那么之前f.widget所占有的资源就泄露了。于是,我们就必须在使用placement new之前,显式调用widget的析构函数来清理掉原来widget占有的资源。
class Factory
{
private:
Widget widget;
public:
Factory()
{
widget.~Widget(); // 新加了这一句
new (this) Factory("factory");
}
Factory(const char *name) : widget(name) { /* something else useful */ }
};
如果Factory有许多的成员,我们是不是要逐个调用这些成员的析构函数呢?这里高端大气的暴力方法是直接调用Factory自身的析构函数,那么Factory的析构函数会负责帮助我们析构所有的子对象并释放资源(反正我们接下来要一切从头来过,用另一个构造函数构造全新的Factory)。这里我们没有定义Factory的析构函数,那么就会使用编译器提供的默认版本,为我们调用所有子对象,也就是widget的析构函数。
class Factory
{
private:
Widget widget;
public:
Factory()
{
this->~Factory(); // 调用自身的析构函数
new (this) Factory("factory");
}
Factory(const char *name) : widget(name) { /* something else useful */ }
};
看起来有些丑陋,我们在自己的构造函数里,调用了自己的析构函数,然后又调用了另一个构造函数。如果要这样做,我们需要确保Factory的析构函数能够正确处理还没有被完全构造的对象,在这个简单的例子里,默认的析构函数已经足够处理这个问题,不过对于更加复杂的结构,我们还是需要认真考虑,对于这种没有完成构造的对象,析构函数能不能正确处理。
另一个问题,如果Factory有一个虚析构函数,那么Factory类的对象都需要一个虚函数表指针vptr来确保对象能够正确调用它的虚成员函数(包括析构函数)。一般实现在对象构造的一开始,任何基类或子对象的构造函数被调用之前,vptr已经有正确的值了,也是比较符合常理的做法。不过因为标准没有规定给vptr赋值的确切时机,所以并没有什么机制来保证我们一定能够运行正确的析构函数。
因此,为了实现借助其他构造函数完成构造的,我们写出来的代码不太安全。就这个简单的例子有以下方法可以取代这种做法。
- 把“factory”作为第二个构造函数name参数的默认值,直接去掉第一个构造函数即可。
- 把构造逻辑的公共部分抽象出来成为一个private成员函数来专门对未完成初始化对象的初始化动作(不要写成虚函数)。
所以,尽量避免对this指针使用placement new,我们一般能够找到更好的设计来解决这样的需求。如果一定需要,那么务必要审慎考虑上面所提到的这些因素。
使用mtrace监控堆内存的分配与释放
应用程序中经常会使用malloc来分配堆内存,mtrace是glibc中提供的用于追踪堆内存分配与释放的功能。
头文件mcheck.h包含了mtrace()和muntrace()的声明。一旦使用了mecheck.h中声明的函数,编译器就会就将程序所使用的malloc()、realloc()、free()、memalign()函数,都会指向mtrace定义的malloc()、realloc()、free()、memalign()函数。调用mtrace()以后,这些函数会尝试将内存分配和释放的行为记录到MALLOC_TRACE环境变量所指定的文件中,并且调用被替换掉的分配、释放函数。如果MALLOC_TRACE环境变量没有被指定,或者指向的不是有效文件,那么mtrace()就不会有任何效果。调用muntrace()以后,也会停止记录内存分配、释放活动。
#include <mcheck.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#include "../common.h"
void __mtracer_on() __attribute__((constructor));
void __mtracer_off() __attribute__((destructor));
void __mtracer_on()
{
char *p = getenv("MALLOC_TRACE");
/*
* Format of tracebuf is:
* Filename prefix of maximum length of MAX_STR_LEN;
* A DOT ".";
* Process index with maximum length of MAX_IDX_LEN;
*/
char tracebuf[MAX_STR_LEN + sizeof(char) + MAX_IDX_LEN + 1];
if (!p)
{
p = "mtrace";
}
sprintf(tracebuf,
"%." STRINGIFY(MAX_STR_LEN) "s.%." STRINGIFY(MAX_IDX_LEN) "d",
p, getpid());
setenv("MALLOC_TRACE", tracebuf, 1);
atexit(&__mtracer_off);
mtrace();
}
void __mtracer_off()
{
muntrace();
}
#ifndef __COMMON_H__ #define __COMMON_H__ #define MAX_STR_LEN 31 #define MAX_IDX_LEN 5 /* * This is a technique to convert a number defined by macro into literal * string. * * For example: * STRINGIFY(MAX_STR_LEN) * turns into * "31" */ #define __STRINGIFY(x) #x #define STRINGIFY(x) __STRINGIFY(x) #endif /* __COMMON_H__ */
用gcc libmtrace.c -fPIC -shared -o libmtrace.so进行编译,产生libmtrace.so文件。
LD_PRELOAD=./libmtrace.so /bin/echo 42
用上面的命令调用echo程序,但是libmtrace会在echo的主函数开始运行之前,就调用mtrace()开始记录内存分配、释放活动。
然后可以使用一个叫做mtrace的Perl脚本小工具,分析产生的日志文件,找到所有没有释放的内存分配。
如果程序包含了编译信息,那么mtrace得到的结果就更详细,可以包含内存泄漏发生的源文件及行号信息。
e820与kernel物理内存映射
我们都对操作系统如何管理内存有一定的了解,然而,在操作系统开始管理内存之前,首先要获取物理内存的信息,比如一共有多少物理地址是可用的,有哪些物理地址是被ACPI(Advanced Configuration and Power Interface)数据使用,这些信息从何而来呢?
e820就是BIOS像x86架构(包括x86_64)上的操作系统引导程序提供物理内存信息的功能。当请求BIOS中断号15H,并且置操作码AX=E820H的时候,BIOS就会向调用者报告可用的物理地址区间等信息,e820由此得名。
Linux内核也通过这种机制来获得物理地址信息,使用dmesg可以看到相关的信息:
[ 0.000000] BIOS-provided physical RAM map: [ 0.000000] BIOS-e820: 0000000000000000 - 000000000009e800 (usable) [ 0.000000] BIOS-e820: 000000000009e800 - 00000000000a0000 (reserved) [ 0.000000] BIOS-e820: 00000000000e0000 - 0000000000100000 (reserved) [ 0.000000] BIOS-e820: 0000000000100000 - 0000000020000000 (usable) #511MB [ 0.000000] BIOS-e820: 0000000020000000 - 0000000020200000 (reserved) [ 0.000000] BIOS-e820: 0000000020200000 - 0000000040000000 (usable) #510MB [ 0.000000] BIOS-e820: 0000000040000000 - 0000000040200000 (reserved) [ 0.000000] BIOS-e820: 0000000040200000 - 00000000aac0d000 (usable) #1706MB [ 0.000000] BIOS-e820: 00000000aac0d000 - 00000000aad8e000 (reserved) [ 0.000000] BIOS-e820: 00000000aad8e000 - 00000000aad95000 (usable) [ 0.000000] BIOS-e820: 00000000aad95000 - 00000000aad96000 (reserved) [ 0.000000] BIOS-e820: 00000000aad96000 - 00000000aad97000 (usable) [ 0.000000] BIOS-e820: 00000000aad97000 - 00000000aadb8000 (reserved) [ 0.000000] BIOS-e820: 00000000aadb8000 - 00000000aadc6000 (usable) [ 0.000000] BIOS-e820: 00000000aadc6000 - 00000000aade8000 (reserved) [ 0.000000] BIOS-e820: 00000000aade8000 - 00000000aaf23000 (usable) [ 0.000000] BIOS-e820: 00000000aaf23000 - 00000000aafe8000 (ACPI NVS) [ 0.000000] BIOS-e820: 00000000aafe8000 - 00000000aaffd000 (usable) [ 0.000000] BIOS-e820: 00000000aaffd000 - 00000000ab000000 (ACPI data) [ 0.000000] BIOS-e820: 00000000ab000000 - 00000000b0000000 (reserved) [ 0.000000] BIOS-e820: 00000000e0000000 - 00000000e4000000 (reserved) [ 0.000000] BIOS-e820: 00000000fec00000 - 00000000fec01000 (reserved) [ 0.000000] BIOS-e820: 00000000fed10000 - 00000000fed14000 (reserved) [ 0.000000] BIOS-e820: 00000000fed18000 - 00000000fed1a000 (reserved) [ 0.000000] BIOS-e820: 00000000fed1c000 - 00000000fed20000 (reserved) [ 0.000000] BIOS-e820: 00000000fee00000 - 00000000fee01000 (reserved) [ 0.000000] BIOS-e820: 00000000ff980000 - 00000000ffc00000 (reserved) [ 0.000000] BIOS-e820: 00000000ffd80000 - 0000000100000000 (reserved) [ 0.000000] BIOS-e820: 0000000100000000 - 000000014f800000 (usable) #1272MB
上面是我在自己计算机上得到的数据,其中usable的区间就是实际被映射到物理内存上的地址空间,上面标注出来的四个区间,就是我主要的四个可用的物理地址区间了,大约4GB。
- Usable:已经被映射到物理内存的物理地址。
- Reserved:这些区间是没有被映射到任何地方,不能当作RAM来使用,但是kernel可以决定将这些区间映射到其他地方,比如PCI设备。通过检查/proc/iomem这个虚拟文件,就可以知道这些reserved的空间,是如何进一步分配给不同的设备来使用了。
- ACPI data:映射到用来存放ACPI数据的RAM空间,操作系统应该将ACPI Table读入到这个区间内。
- ACPI NVS:映射到用来存放ACPI数据的非易失性存储空间,操作系统不能使用。
- Unusable:表示检测到发生错误的物理内存。这个在上面例子里没有,因为比较少见。
内核读到这些信息后,将其保存在e820map结构体中,有两个副本,一个符号名叫e820,还有一个符号名叫e820_saved。具体的数据结构可以参考arch/x86/include/asm/e820.h。随着内核的启动,内核还会修改e820的信息。
[ 0.000000] e820 update range: 0000000000000000 - 0000000000010000 (usable) ==> (reserved) [ 0.000000] e820 remove range: 00000000000a0000 - 0000000000100000 (usable) [ 0.000000] e820 update range: 00000000ab000000 - 0000000100000000 (usable) ==> (reserved)
比如在我的系统上发生了这样三次e820的改动,这些改动已经与BIOS没有任何关系了,只是内核自己通过修改自己的内存数据结构,来改变自己对内存区间的使用。
还有一个典型的例子是当内核启动参数中有置顶memmap这样的参数项时,内核会修改指定的usable的区间为reserved,这样内核就不能将虚拟地址映射到这些物理地址空间了,换言之就是不能使用这块物理内存了(其实通过ioremap还是可以将其映射到内核的虚拟地址空间的,但是这些行为都是自己控制的而不会受到其他程序的干扰)。这样当我们需要自己管理某段物理内存而不希望内核干预时就很有用处,比如基于物理内存的文件系统,就可以这样实现。
内核中还提供了一系列操作e820数据结构的函数,函数声明都在arch/x86/include/asm/e820.h,相应的定义都在arch/x86/kernel/e820.c中。文章开头看到的这段信息,就是由void __init e820_print_map(char *who)来打印的。
在这个过程中,e820_saved始终保持原始的状态不变,以便查询BIOS提供的真实映射信息,不过内核目前好像没有使用这个数据结构。我曾经有使用过它,用来检查某个物理地址是否确实是物理内存。
GCC __builtin_expect与kernel指令序列优化
在内核级的开发过程中,代码运行速度尤为重要,让我们先看两段汇编代码。
.LC1: .string "Hula!" .LC2: .string "Woo~" call __isoc99_scanf movl 28(%esp), %eax testl %eax, %eax je .L2 movl $.LC1, (%esp) call puts .L3: xorl %eax, %eax leave ret .L2: movl $.LC2, (%esp) call puts jmp .L3
.LC1: .string "Hula!" .LC2: .string "Woo~" call __isoc99_scanf movl 28(%esp), %eax testl %eax, %eax jne .L5 movl $.LC2, (%esp) call puts .L3: xorl %eax, %eax ret .L5: movl $.LC1, (%esp) call puts jmp .L3
上面两段代码为了方便阅读,都省略了一些与本次主题无关的代码。稍微阅读一下就可以发现,这两段代码做的事情其实是一样的。这是一个简单的if分支结构的编译结果,两段代码的差异在于是讲if段还是else段放在前面。这两者有着什么样的区别呢?
这要从现代的处理器架构说起。相信大家都知道流水线技术,就是CPU可以在统一个时钟周期内同时执行多条指令,当前指令尚未执行完毕,实际上就已经开始处理后面的指令了。然而当处理器遇到分支的时候,就无法判断即将执行的是哪个分支,流水线优化就受到了限制。
后来,随着处理器技术的发展,处理器开始直接预取分支后面的指令,如果发现分支预判错误,则抛弃之前的执行结果,重新转入正确的分支继续执行。更加现代的处理器甚至能够预取更多后面的指令,对于不依赖之前执行结果的指令都可以按照一定的规则预先执行得到结果。
再看上面的例子,我们就明白了,直接连接在je或者jne指令后面的分支可以在分支条件判断结束之前就开始运行,因此执行速度会更快,相反另一条分支则会慢一些。
在这个例子中两个分支都非常短,在更复杂的情况下,如果单个分支就很长,那么预取正确的指令还有助于Cache的命中。
GCC提供了__builtin_expect宏,作为编译分支时候的暗示。用法是__builtin_expect(var, expected_value),也就是说,告诉编译器var这个变量的值比较可能是什么。在kernel中这个宏被用在likely和unlikely这两个宏定义中:
#define likely(x) __builtin_expect(!!(x), 1) #define unlikely(x) __builtin_expect(!!(x), 0)
显而易见,这两个宏的意思是,条件x是很有可能成立,还是很有可能不成立。
int main()
{
int a;
scanf("%d", &a);
if (likely(a))
{
printf("Hula!\n");
}
else
{
printf("Woo~\n");
}
return 0;
}
上面第一段汇编代码,实际上就是这个程序编译产生的。相应的,把likely改为unlikely,就可以得到第二段的汇编代码。
在内核中,比如就绪队列不太可能为空,runqueue里的所有任务很有可能都在CFS queue里,以及一些很少见的竞争与冒险的情况,都有针对性地使用这种技术进行了优化。
GCC typeof在kernel中的使用——C语言的“编译时多态”
大家都知道,C语言本身没有多态的概念,函数没有重载的概念。然而随着C语言编写的软件逐渐庞大,越来越多地需要引入一些其他语言中的特性,来帮助更高效地进行开发,Linux kernel是一个典型例子。
在动态类型的语言里面,往往有typeof这种语法,来获取变量的数据类型,比如JavaScript当中,typeof以字符串型式返回了这个变量的数据类型,借由这种特性,往往可以根据传入参数的类型不同,产生不同的行为。
GCC提供的typeof,实际上是在预编译时处理的,最后实际转化为数据类型被编译器处理。用法上也和上述语言不太一样。
基本用法是这样的:
int a; typeof(a) b; //这等同于int b; typeof(&a) c; //这等同于int* c;
那么在内核中这种特性是怎样使用的呢?
/*
* Check at compile time that something is of a particular type.
* Always evaluates to 1 so you may use it easily in comparisons.
*/
#define typecheck(type,x) \
({ type __dummy; \
typeof(x) __dummy2; \
(void)(&__dummy == &__dummy2); \
1; \
})
/*
* Check at compile time that 'function' is a certain type, or is a pointer
* to that type (needs to use typedef for the function type.)
*/
#define typecheck_fn(type,function) \
({ typeof(type) __tmp = function; \
(void)__tmp; \
})
这两段代码来自于include/linux/typecheck.h,用于数据类型检查。
宏typecheck用于检查x是否是type类型,如果不是,那么编译器会抛出一个warning(warning: comparison of distinct pointer types lacks a cast);而typecheck_fn则用于检查函数function是否是type类型,不一致则抛出warning(warning: initialization from incompatible pointer type)。
原理很简单,对于typecheck,只有当x的类型与value一致,&__dummy == &__dummy2的比较才不会因为类型不匹配而抛出warning,详情可以参考C语言对于指针操作的标准规定。对于typecheck_fn,当然也只有function的返回值和参数表与type描述一致,才不会因为类型不匹配而抛出warning。
到这里有人可能会有一个疑问,内核代码里执行类型检查会不会降低效率?答案是不会的,因为实际上,这些为类型检查而声明的临时变量,实际上在上下文中都没有使用,并且还特别地强制类型转换为void防止任何由这些临时变量产生的结果被使用的情况,因此在编译器优化时,就将这些无用的代码删除了。
然后kernel中还定义了使用另一种类型检查策略的获取最大最小值的宏。
/*
* ..and if you can't take the strict
* types, you can specify one yourself.
*
* Or not use min/max/clamp at all, of course.
*/
#define min_t(type, x, y) ({ \
type __min1 = (x); \
type __min2 = (y); \
__min1 < __min2 ? __min1: __min2; })
#define max_t(type, x, y) ({ \
type __max1 = (x); \
type __max2 = (y); \
__max1 > __max2 ? __max1: __max2; })
这个例子里面不要求x和y是严格等于type类型,只要x和y能够安全地完成隐式类型转换为type就可以安全通过编译,否则会抛出warning。
另外一个非常经典的例子就是交换变量。
/*
* swap - swap value of @a and @b
*/
#define swap(a, b) \
do { typeof(a) __tmp = (a); (a) = (b); (b) = __tmp; } while (0)
试想如果没有typeof,要怎么在C语言中实现这种类似C++模板的特性呢?
最后不得不提的就是container_of宏,在kernel中也被广泛使用。
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
比如内核的task_struct数据结构中有一个member是sched_entity类型的se,这个member常常被调度器使用来决定进程的调度顺序,那么如果要根据这个se来获取包含它的task_struct,就可以使用container_of(p, task_struct, se)来实现(假设p是指向这个sched_entity的指针)。原理是先产生一个指针指向member,然后将这个指针减去member在这个struct中的偏移量,指针自然就指向了包含该member的对象了(这个地方用到了offsetof,含义一看便知,我就不再细说了)。
希望大家对typeof的使用有了一个更好的理解,欢迎评论!
Data Deduplication in Backup and Recovery
In recent years, big data is being mentioned everywhere, and the protection of data has been highly concerned.
Years ago, data were backed up into tapes, which are storage devices with high capacity, good at sequential access but poor enough in random access. Administrators used to make weekly full backup and daily incremental backup in order to balance between backup speed, size of backup set and mean time to recover.
We need to know what is the difference between backup storage and transactional storage. The most significant difference is the backup storage is written frequently but hardly read, always sequantially accessed instead of randomly. In that case, we need to reduce the size of backup set to increase the logical data protected without increasing physical storage. Compression is a good idea to reduce data size, and in practise, it can compress data by approximately 50%. However this is still very far from the ideal target of space saving. That' why we introduce the deduplication technology, that is, generally, save only one copy of identical data.
There are several ways to split logical data into parts. We can split the data file-based, block-based or segment-based. Segment here stands for chunks of data which sizes are not fixed.
In file-based deduplication, backup system can detect identical files in the storage system, such as two or more same files are stored in different logical directories. Obviously, once the file is slightly changed, deduplication is not applicable.
In block-based deduplication, backup system can detect identical blocks in the storage system. This method is fine-grained, so the detection of identical blocks will be applied on every single block in each file. Generally, it will be able to save more space than file-based way. However, when data insertion happens in a block, significant data shuffle will happen in subsequent data blocks, resulting in the inapplicability of deduplication on those blocks.
Segment-based deduplication is introduced to solve this problem. Each file is detected and splitted into segments by a certain algorithm. This algorithm will try to detect logical segments of file, and keep the segment size in a reasonable value. For example, in a plain text file, the algorithm may split the file by paragraph, that is to detect new line characters. Of course, different patterns are applied to different data format to ensure better logical separation of data. Since the file is separated in logical patterns, so we are more likely to benefit from data deduplication through this way.
While single algorithm is hard to detect so many different file formats, so data producer can provide us with the most suitable separation algorithm as a plugin to the deduplication feature, to help the file it produced to be more logically understood.
In order to implement this, we need to build an index to store the metadata for every segment, so that we will be able to tell whether some data are added, removed or modified.