赋值语句、求值顺序和序列点
这个问题缘起网上著名的a=b=c的讨论,各种语言都有针对这个细节问题的讨论。
让我们来看一看这连续赋值在各种语言的行为,以及表象背后的语言设计本身。
y = x = {a : 1};
document.write(y.a + " " + x.a + "\n");
结果输出1和1,没有什么问题,如果不考虑y和x的作用域上可能存在的差别,上面的代码就相当于:
x = {a : 1};
y = x;
关于Javascript赋值语句的语义,可以参考http://deltamaster.is-programmer.com/posts/43687.html这篇文章。
而这个时候我又在网上发现了关于一种诡异代码的讨论:
x.n = x = {a : 2};
document.write(x.n + " " + x.a + "\n");
结果是undefined和2。这个时候如果我把这个语句拆开来写成两句,结果就不是这样:
x = {a : 2};
x.n = x;
document.write(x.n.a + " " + x.a + "\n");
这时候输出的结果是2和2。那么问题就来了,为什么这种情况下结果不同呢?
经过翻阅ECMAScript标准相关章节http://www.ecma-international.org/ecma-262/5.1/#sec-11.13,找到了蛛丝马迹。根据标准规定,对于赋值语句,总是先对lhs求值,再对rhs求值,然后PutValue。然后来看看求值顺序对结果的影响,我们一步一步来分析上面这条语句。
假设执行语句之前,x是一个空对象。第一步,首先对x.n进行求值,x没有属性n,那么为x添加属性n,左值的求值结果就是对刚才添加的属性n的引用。
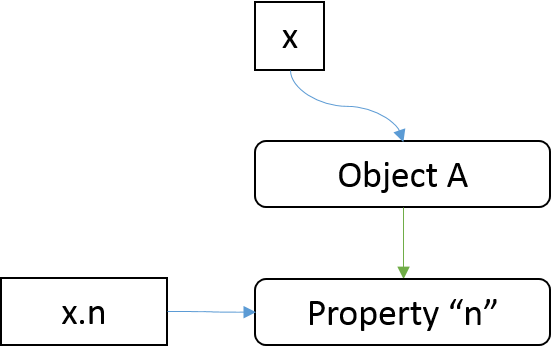
上面图中蓝色箭头表示引用关系。
第二步对右值进行求值,右值是x = {n : 2}。递归向下,先对左值求值,得到x,按照上图的话,应该也是引用Object A,然后对右值{a : 2}求值,得到Object B,接着PutValue将改变x的引用目标到Object B,赋值表达式x = {n : 2}返回Object B。
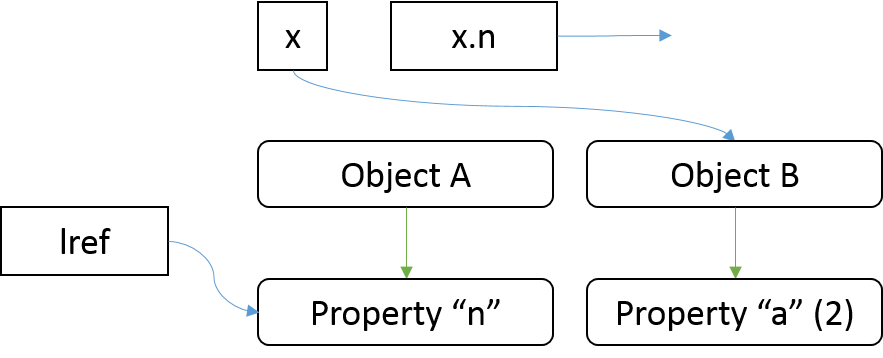
这个时候x和Object A已经解绑,那么相应的x.n也已经和Object A无关了,x.n的指向与刚才第一步求值得到的引用也没有了联系,而Object B这时候没有属性n,所以x.n这个时候是undefined。
第三步,PutValue将lref指向Object B。不过这个时候lref指向的属于Object A的属性n,已经没有被其他资源指向了,Object A的属性n也不再是x的属性n。
这样整个赋值过程就完成了,得到了x.n为undefined的结果。
让我们再来看看用C++尝试做类似的事情会是什么结果(下面的代码请使用支持C++11语法的编译器编译):
#include <iostream>
class A;
class A
{
public:
A* n = nullptr;
int a = 0;
};
int main()
{
A o;
o.a = 2;
A x;
x.n = &(x = o);
std::cout << x.n->a << std::endl;
return 0;
}
输出的结果是2。不过,这时候编译器给出了警告:main.cpp|18|warning: operation on 'x' may be undefined [-Wsequence-point]|。
这里面有两个问题。第一,C++的赋值语句返回的是左值,而其他许多语言(包括C语言,还有上面提到的Javascript)返回的是右值。因此上面的代码x.n = &(x = o)在C语言中是无法通过编译的,因为取地址运算的操作数必须是左值。第二,C、C++有序列点的概念,在两个序列点之间,如果发生多次副作用,那么这些副作用发生的顺序是不确定的(可以自行搜索关于“序列点”和“副作用”),只是在上面的这个实验中,x = o的副作用先发生了。
Dec 14, 2022 08:42:20 PM
In programming, an assignment statement is a statement that assigns a value to a variable. The order of evaluation in an assignment statement refers diamond rings to the order in which the different parts of the statement are evaluated by the programming language. A sequence point is a point in the execution of a program where all previous operations have been completed and no further operations can be initiated until the next sequence point is reached. Good to see the details shared over here.
Mar 06, 2024 06:30:45 PM
You are travel lovers? Where will you go for the next destination? Let things to do post show you their favorite places with their beautiful photos