使用mtrace监控堆内存的分配与释放
应用程序中经常会使用malloc来分配堆内存,mtrace是glibc中提供的用于追踪堆内存分配与释放的功能。
头文件mcheck.h包含了mtrace()和muntrace()的声明。一旦使用了mecheck.h中声明的函数,编译器就会就将程序所使用的malloc()、realloc()、free()、memalign()函数,都会指向mtrace定义的malloc()、realloc()、free()、memalign()函数。调用mtrace()以后,这些函数会尝试将内存分配和释放的行为记录到MALLOC_TRACE环境变量所指定的文件中,并且调用被替换掉的分配、释放函数。如果MALLOC_TRACE环境变量没有被指定,或者指向的不是有效文件,那么mtrace()就不会有任何效果。调用muntrace()以后,也会停止记录内存分配、释放活动。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | #include <mcheck.h>#include <unistd.h>#include <stdlib.h>#include <string.h>#include <stdio.h>#include "../common.h"void __mtracer_on() __attribute__((constructor));void __mtracer_off() __attribute__((destructor));void __mtracer_on(){ char *p = getenv("MALLOC_TRACE"); /* * Format of tracebuf is: * Filename prefix of maximum length of MAX_STR_LEN; * A DOT "."; * Process index with maximum length of MAX_IDX_LEN; */ char tracebuf[MAX_STR_LEN + sizeof(char) + MAX_IDX_LEN + 1]; if (!p) { p = "mtrace"; } sprintf(tracebuf, "%." STRINGIFY(MAX_STR_LEN) "s.%." STRINGIFY(MAX_IDX_LEN) "d", p, getpid()); setenv("MALLOC_TRACE", tracebuf, 1); atexit(&__mtracer_off); mtrace();}void __mtracer_off(){ muntrace();} |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #ifndef __COMMON_H__#define __COMMON_H__#define MAX_STR_LEN 31#define MAX_IDX_LEN 5/* * This is a technique to convert a number defined by macro into literal * string. * * For example: * STRINGIFY(MAX_STR_LEN) * turns into * "31" */#define __STRINGIFY(x) #x#define STRINGIFY(x) __STRINGIFY(x)#endif /* __COMMON_H__ */ |
用gcc libmtrace.c -fPIC -shared -o libmtrace.so进行编译,产生libmtrace.so文件。
1 | LD_PRELOAD=./libmtrace.so /bin/echo 42 |
用上面的命令调用echo程序,但是libmtrace会在echo的主函数开始运行之前,就调用mtrace()开始记录内存分配、释放活动。
然后可以使用一个叫做mtrace的Perl脚本小工具,分析产生的日志文件,找到所有没有释放的内存分配。
如果程序包含了编译信息,那么mtrace得到的结果就更详细,可以包含内存泄漏发生的源文件及行号信息。
随机数种子的选择
随机数生成器的质量七绝于其产生的序列是否在任意输入下拟合均匀分布,相对而言,选择一个优秀的随机数生成器不是件特别困难的事情,然而选择优质的随机数种子却有许多需要注意的地方。在只需要产生拟合均匀分布的随机序列时,选取随机数种子没有特别的要求。然而随机数生成器往往会被用于产生密钥的哈希算法,此时对于种子的选取就有特定的要求。
有一些反面教材可供参考:
1995年9月时,当时流行的Netscape浏览器使用当前时间、当前Netscape的进程号和父进程号产生随机数种子。当时加州大学伯克利分校的研究员就实现了暴力破解Netscape的加密信息。
另一个例子是Kerberos协议的v4版本,它将当前时间与一些其他信息异或起来产生随机数种子。这个异或位运算直接将其他有效的信息屏蔽了,只留下20位容易预测的值,将密钥的空间从72万亿左右直接减少到1百万多一点,几秒钟时间就可以被暴力破解。
在选择随机数种子的时候容易犯下面这些错误:
- 从一个很小的空间里选取种子:如果你选择的随机数种子只有8位长度,那么无论随机算法怎样,都最多只有256种可能的随机数序列。
- 仅将当前时间作为随机数种子:尽管UNIX API返回精确到毫秒级的时间,但是大多数操作系统处理时间的精度都不到1/60秒,那么,即使在1个小时是邻域内,也只有216000种可能的取值,对于暴力破解来说太容易了。
- 自己泄漏随机数种子:如果种子中使用了当前时间作为产生随机数种子的依据之一,那么就不要以任何方式泄露这个信息,例如不要在未加密的消息头部包含被作为随机数种子产生依据的时间信息。
- 使用网卡或硬件序列号:这种信息往往都是结构化的,而非散列的,结构化的信息被穷举的难度大大降低了。
对于选择安全的随机数种子,有一些比较好的方案:
- 使用真正随机的数据源,比如一些噪点,装配相应的传感器,分析传入的信号的噪声,各种自然界的信号都是可以的。当然设备提供的现成的模拟信号也是可以的,例如/dev/audio在没有插入麦克风时提供的随机噪音,cat /dev/audio | compress,压缩一下可以进一步模糊值的实际含义。
- 获取系统底层的数据,也就是只有本机进程才有权限获取到的,不容易猜测到相近值,无法预先缩小取值范围的数据。比如系统当前使用的内存分页情况、CPU的温度、到某点的网络延迟的情况之类的。
- 让用户输入一串字符,分析用户按键的间隔时间,作为产生随机数种子的依据。千万不要只是取一个平均什么的,从统计的规律来看,按键的间隔时间一般也是在一个比较小的区间内的,要做取模、相乘等运算,产生不能预知可能分布情况的无意义的值。当然,要是结合鼠标移动的信息,就更好了。
CRUSH:受控的、可扩展的数据副本分散存储方案(Part 3)
CRUSH:受控的、可扩展的数据副本分散存储方案
3.2 副本位置策略
 ,将作为后续操作的输入。select(n,t)操作对中的每一个元素i进行迭代,选择n个以i节点为根的子树下具有t类型的项。存储设备都有一个已知的、确定的类型,系统中的每个桶有一个类型字段用于区分不同类型的桶(例如,某些代表“rows”,有些代表“cabinets”)。对中的每一个元素i,select(n,t)操作对于1到n之间的每一个数r被迭代调用,n是请求的项数,操作将递归向下经过任何中间节点的桶,用c(r,x)函数(在章节3.4中为每种类型的桶分别定义)伪随机地在每个桶中选中一个被嵌套的项目,直到找到了满足要求类型t的项。结果的
,将作为后续操作的输入。select(n,t)操作对中的每一个元素i进行迭代,选择n个以i节点为根的子树下具有t类型的项。存储设备都有一个已知的、确定的类型,系统中的每个桶有一个类型字段用于区分不同类型的桶(例如,某些代表“rows”,有些代表“cabinets”)。对中的每一个元素i,select(n,t)操作对于1到n之间的每一个数r被迭代调用,n是请求的项数,操作将递归向下经过任何中间节点的桶,用c(r,x)函数(在章节3.4中为每种类型的桶分别定义)伪随机地在每个桶中选中一个被嵌套的项目,直到找到了满足要求类型t的项。结果的 个项,被放回到输入变量,可以作为后续的select(n,t)操作的输入参数,也可以通过emit操作将其移入结果向量。
个项,被放回到输入变量,可以作为后续的select(n,t)操作的输入参数,也可以通过emit操作将其移入结果向量。![图1:某四级集群映射层次结构的部分视图,包含row、cabinet、shelf和disk。粗体字标出的表示在[表1]中描述的Placement Rules和假想的映射关系中,被每次select操作选中的项。](/user_files/deltamaster/Image/图1.png)
| 动作序列 |
结果 |
|---|---|
| take(root) | root |
| select(1,row) | row2 |
| select(3,cabinet) | cab21 cab23 cab24 |
| select(1,disk) | disk2107 disk2313 disk 2437 |
| emit |

[算法1:CRUSH确定对象x的存放位置]
3.2.1 冲突、故障和过载
3.2.2 副本排序
 的对应位置上被替换,其他列表中的设备要维持位置不变(位置就是指在的对应位置,详见[图2])。在这种情况下,CRUSH通过
的对应位置上被替换,其他列表中的设备要维持位置不变(位置就是指在的对应位置,详见[图2])。在这种情况下,CRUSH通过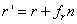 进行重选,其中
进行重选,其中 是第r此迭代时失败的次数,这样就为每一个向量位置上的项定义了一系列候选项,每个候选项与其他位置上的候选项是无关的。相比之下,RUSH对于发生故障的设备没有特殊处理,就像其他现有的散列分布式函数,它隐式地假设使用“前n个”的策略在结果中跳过失效的设备,在奇偶校验这样的模式下就难以使用了。
是第r此迭代时失败的次数,这样就为每一个向量位置上的项定义了一系列候选项,每个候选项与其他位置上的候选项是无关的。相比之下,RUSH对于发生故障的设备没有特殊处理,就像其他现有的散列分布式函数,它隐式地假设使用“前n个”的策略在结果中跳过失效的设备,在奇偶校验这样的模式下就难以使用了。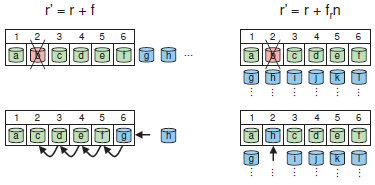 。左边表示“前n个”方案,已有设备(c、d、e、f)的序号可能发生改变。在右边,每个序号都有独立的一系列可能的目标,在这里=1,且=8(设备h)。]
。左边表示“前n个”方案,已有设备(c、d、e、f)的序号可能发生改变。在右边,每个序号都有独立的一系列可能的目标,在这里=1,且=8(设备h)。]3.3 映射变更与数据移动
 (其中W是所有设备的权重总和),因为只有失效设备上的数据被移动了。
(其中W是所有设备的权重总和),因为只有失效设备上的数据被移动了。 。在层次结构的每一层,每一次相关子树的权值改变,都要改变数据分布,一部分数据对象就需要从权值下降的子树移动到权值上升的子树中。由于层次结构中每个节点上的伪随机位置决策在统计意义上是相互独立的,移入某个子树的数据被均匀地分布在那一点下,而且并不一定需要被重新映射到直接导致权值变化的那个叶子节点中。只有在定位过程相对比较深的层次,才会为维持总体的数据分布而移动数据。在一个二叉树结构中的大致效果在[图3]中进行了展示。,这一部分数据会被移动到新增的权值为
。在层次结构的每一层,每一次相关子树的权值改变,都要改变数据分布,一部分数据对象就需要从权值下降的子树移动到权值上升的子树中。由于层次结构中每个节点上的伪随机位置决策在统计意义上是相互独立的,移入某个子树的数据被均匀地分布在那一点下,而且并不一定需要被重新映射到直接导致权值变化的那个叶子节点中。只有在定位过程相对比较深的层次,才会为维持总体的数据分布而移动数据。在一个二叉树结构中的大致效果在[图3]中进行了展示。,这一部分数据会被移动到新增的权值为 的设备上。数据的移动量随着层次结构的高度h的增加而增加,数据移动量渐进地趋向
的设备上。数据的移动量随着层次结构的高度h的增加而增加,数据移动量渐进地趋向 。当相对于W足够小的时候,数据的移动量就趋近于上界,因为递归过程的每一步数据对象移动到一颗子树时,被映射到权值很小的项上的概率很小。
。当相对于W足够小的时候,数据的移动量就趋近于上界,因为递归过程的每一步数据对象移动到一颗子树时,被映射到权值很小的项上的概率很小。
3.4 桶的类型
| 项目名 | Uniform | List | Tree | Straw |
| 速度 | O(1) | O(n) | O(log n) | O(n) |
| 添加项 | 差 | 最优 | 好 | 最优 |
| 移除项 | 差 | 差 | 好 | 最优 |
3.4.1 Uniform Bucket
 ,根据一些数论原理,我们总能够根据输入选出各不相同的项。[注释2:等差数列的素数定理[Granville 1993]说明了,这个函数会提供mφ(m)种不同的方式,将对象x的副本进行分发,每种分发方式的选取都是等概率的,φ()是欧拉φ函数。]对于
,根据一些数论原理,我们总能够根据输入选出各不相同的项。[注释2:等差数列的素数定理[Granville 1993]说明了,这个函数会提供mφ(m)种不同的方式,将对象x的副本进行分发,每种分发方式的选取都是等概率的,φ()是欧拉φ函数。]对于 的情况这一点就无法保证了,这表示同一个输入的两个不同副本也许会被映射到同一个项中。实际应用中,这就表示位置算法产生冲突并导致后续的回溯动作并不是不可能的(详见[章节3.2.1])。
的情况这一点就无法保证了,这表示同一个输入的两个不同副本也许会被映射到同一个项中。实际应用中,这就表示位置算法产生冲突并导致后续的回溯动作并不是不可能的(详见[章节3.2.1])。3.4.2 List Bucket
3.4.3 Tree Bucket
3.4.4 Straw Bucket
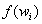 进行缩放,因此权值较大的项比较容易胜出,即
进行缩放,因此权值较大的项比较容易胜出,即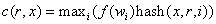 。[注释3:尽管的简单封闭形式还没有找到,但通过程序方式来计算权值因子还是比较简单易行的(源代码可供参考)。只有在桶发生修改时,才需要重新计算一次这个因子。]尽管这一过程要比List Bucket慢上(平均)几乎一倍,比Tree Bucket(对数数量级)更慢,Straw Bucket却提供了修改时嵌套项间的最佳数据移动。
。[注释3:尽管的简单封闭形式还没有找到,但通过程序方式来计算权值因子还是比较简单易行的(源代码可供参考)。只有在桶发生修改时,才需要重新计算一次这个因子。]尽管这一过程要比List Bucket慢上(平均)几乎一倍,比Tree Bucket(对数数量级)更慢,Straw Bucket却提供了修改时嵌套项间的最佳数据移动。
CRUSH:受控的、可扩展的数据副本分散存储方案(Part 2)
CRUSH:受控的、可扩展的数据副本分散存储方案
2 相关工作
3 CRUSH算法
3.1 层次化Cluster Map
CRUSH:受控的、可扩展的数据副本分散存储方案(Part 1)
CRUSH:受控的、可扩展的数据副本分散存储方案
摘要
1 简介
在C++中使用成员函数指针
函数指针的语法相对比较复杂,成员函数指针则在此基础上进一步引入了类作用域限定。让我们来了解一下成员函数指针的写法。
首先回顾一下函数指针的使用方法。有这样一个函数:
1 2 3 4 | double func(double x){ return 3.14 * x;} |
我们这样声明函数指针,并且进行调用:
1 2 3 | double (*pfunc)(double x);pfunc = &func;cout << (*pfunc)(1.1) << endl; |
指针的声明包括返回类型、指针名和函数的参数表,对于一个强类型的编译型语言,这些要素都必不可少。由于运算符优先级的规定,还要特别注意在适当的位置加上括号。
对于成员函数指针,就是增加了一个作用域限定。
首先有一个类A,包含几个类型相同的函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | class A{public: void f1(int x) { cout << "f1:" << x << endl; } void f2(int x) { cout << "f2:" << x << endl; } void f3(int x) { cout << "f3:" << x << endl; }}; |
然后类B的对象会调用类A的对象的成员函数,然而具体调用哪一个还不知道,我们通过指针的方式来实现,在运行时将指针指向一个类型兼容的成员函数。
1 2 3 4 5 6 7 8 9 10 11 | class B{public: void (A::*pf) (int x); //注意作用域运算符和*的次序,括号不能省略 void callF(int x) { A a; (a.*pf)(x); }}; |
我们在外部实例化B的对象,然后为B的成员函数指针赋值,确定将要调用的是哪一个函数。
1 2 3 4 | cout << "Hello world!" << endl;B b;b.pf = &A::f2;b.callF(5); |