算法复杂度不等于性能,list的性能陷阱
在学习数据结构和算法的时候,我们一般都会通过分析算法复杂度,来对某个问题选择合适的数据结构和算法。
下面就是一个经典问题:
我们需要一个容器,容器中存放的是int数据。容器中的元素是有序的,对容器有一个插入操作,要求是插入后容器中的元素仍然是有序的。我们应该选择list还是vector?
让我们先从算法复杂度的角度来简单看一下这个问题。首先一点是有序,所以找到要插入的位置,对于list的算法复杂度是O(n),因为平均需要遍历一半的链表长度,对于vector的算法复杂度是log^2(n),因为可以进行二分查找确定位置。然后是插入,list的插入操作是O(1),非常理想的常数级操作,而vector的插入操作是O(n),因为平均要移动一半的元素。综合下来看,list是要更胜一筹,所以应该选择list。但是事实却与这个推测截然相反?
让我们用C++写一段程序来进行验证:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | #include <iostream>#include <vector>#include <list>#include <random>using namespace std;template <typename T>typename T::iterator insert(T& c, typename T::value_type elem){ auto i = c.begin(); for (; i != c.end(); i++) { if (elem <= *i) { break; } } return c.insert(i, elem);}int main(int argc, char** argv){ vector<int> v; list<int> l; auto engine = default_random_engine(); if (argc < 3) return 1; if (argv[1] && argv[1][0] == 'v') { for (int i = 0; i < atoi(argv[2]); i++) { insert(v, engine()); } } else { for (int i = 0; i < atoi(argv[2]); i++) { insert(l, engine()); } } return 0;} |
在这里为了说明问题方便起见,在查找阶段我们让vector和list都使用O(n)的方法进行查找。那么对于这段程序(下面表里的算法复杂度是针对每次插入操作而言的):
| locate | insert | |
| vector | O(n) | O(n) |
| list | O(n) | O(1) |
这样,我们通过生成一系列随机数的方式来进行测试。让我们看看不同数据规模下的测试结果如何,表格中的时间单位是秒。
| 规模 | vector | list |
| 100 | 0.002 | 0.003 |
| 1000 | 0.003 | 0.004 |
| 10000 | 0.019 | 0.142 |
| 100000 | 1.153 | 29.504 |
为什么list的性能反而差,而且相差如此悬殊?因为我们之前没有站在体系结构的角度看问题。同样是O(n)的操作,对于计算机而言实际执行的效率可能有着天壤之别。
让我们回顾一下前面程序中的insert函数模板,对于两种容器,我们使用了完全相同的线性查找算法。对于计算机而言,list版本的步进操作(i++),需要多进行一次寻址(根据指针找到下一个节点的位置),而更重要的是,找到的下一个节点,很有可能没有命中缓存,因为通过list中的相邻元素在内存中并没有相邻关系;而vector的步进操作,几乎能够保证命中缓存,因为每次访问的,都是内存中相邻的元素。对于插入操作而言,list虽然只有O(1)复杂度,而且确实非常快,但却要每次进行一次很小的内存分配,而又因为list的每个节点都要包含其他指针信息,对于内存空间也是很大的浪费。
我们从这个测试中得到的启示是:
- 性能分析要用实际测试数据说话,主观推测容易以偏概全;
- 对于体系结构的理解非常重要,缓存命中率是影响性能的重要因素;
- 数据规模小的时候,算法复杂度无关紧要;
- 不要过度优化;
- 节约使用内存!
优雅的接口设计无需为性能妥协——C++ Copy Elision
许多程序员,尤其是很多稍有一些经验的C++程序员,会陷入一种为了性能而牺牲接口设计可维护性的误区,最终往往在性能上提升很少,甚至没有提高,程序可维护性也大大降低,这是我们都不希望看到的结果。
下面是一个典型的例子,当然进行了一定的抽象和简化。
1 2 3 4 5 6 7 8 9 10 11 | void getA(A& x){ // do some initialization to "x"}void f(){ A a; getA(a); // use "a"} |
我问,为什么不设计成“A getA()”,让对象a在函数getA中进行构造呢?这样接口就更加容易阅读,一般并不鼓励将参数作为输出参数来使用,这样会降低程序的可读性。
他给出的答案是,这样可以避免对象的拷贝构造,能够提升性能。因为如果在getA中构造了A的对象,那么在返回时要调用一次拷贝构造函数将这个对象拷贝构造到调用处,然后再析构getA中临时产生的对象。
事实果真如此吗?让我们阅读一下C++标准的相关章节。
When certain criteria are met, an implementation is allowed to omit the copy/move construction of a class object, even if the constructor selected for the copy/move operation and/or the destructor for the object have side effects. In such cases, the implementation treats the source and target of the omitted copy/move operation as simply two different ways of referring to the same object, and the destruction of that object occurs at the later of the times when the two objects would have been destroyed without the optimization. This elision of copy/move operations, called copy elision, is permitted in the following circumstances (which may be combined to eliminate multiple copies):
- in a return statement in a function with a class return type, when the expression is the name of a non-volatile automatic object (other than a function or catch-clause parameter) with the same cv-unqualified type as the function return type, the copy/move operation can be omitted by constructing the automatic object directly into the function’s return value
让我们根据上面条款来看看,下面的代码会怎么处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 | A getA(){ A x; // logically construct "x" here, but actually not // do some initialization to "x" return x; // logically copy-construct "x" to "a" here, but actually not // logically destruct "x", but actually not}void f(){ A a = getA(); // actually construct "x" directly here // use "a"} |
根据标准说明,函数getA的返回值是类型A,并且与返回类型一样是non-const、non-volatile对象,也是automatic对象(逻辑上被分配到栈上),从对象x到调用处(f函数中的变量a)的拷贝构造可以被省略,对象x将会被直接构造在f函数的变量a处(getA中的x和f中的a将被视为同一个对象)。即使拷贝构造函数中有任何副作用,这个调用也仍然可以被省略,并且这种行为被视为正常的语义,而非优化行为。
在gcc编译器中,即使指定优化级别为0,在上面的例子中也不会有两个A对象被构造;而Visual Studio指定了一定优化级别以后,多余的对象构造也会被省略。
因此,第一种写法能够提升性能的说法并不成立,而且接口设计相当丑陋难读。相反,有时第一种写法甚至会损害性能。
请看下面的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | A::A(int x, int y, int z) : x(x), y(y), z(z) {}A getA(){ // get height, width, length from somewhere else A x(height, width, length); return x;}void f(){ A a = getA(); // use "a"} |
这段代码说A有一种接受三个参数的构造函数,而这三个参数在getA中可以通过某些逻辑得到,那么可以直接通过带参数的构造函数对A进行初始化,这个带参数的构造函数直接用高效的冒号语法进行初始化。反观第一种方案,如果获取三个参数的逻辑对于函数f是不可见的,那么我们就必须要首先默认构造A对象,然后再进行赋值操作对A对象进行初始化,非但性能低下,且代码丑陋难以维护。
在C++11中引入了右值引用的概念,即使有编译器决定将x构造在getA内部,再用它来构造对象a,这种情形也适用move constructor,而几乎没有可观的性能损耗。当然,在这种情况下,即使定义了move constructor,gcc也不会调用它。
所以,我们不应该想当然地对代码进行优化,尤其是在要牺牲代码可读性的情况下更加应该慎重:
- 首先应该考察,是否确实存在性能低下(在这个例子中没有)
- 如果性能低下,则需考察这个性能问题是否是系统性能的瓶颈
- 如果是,是否能够借助编译器优化提升性能,或者局部性地改变代码使得编译器更容易优化,或许会影响一定的代码的可读性,但对于接口的可读性没有影响
- 如果仍然无法改善,才有可能考虑牺牲接口的可读性
C++构造自动推导模板类型的function adaptor(STL Function Adaptor)
继续前一篇文章http://deltamaster.is-programmer.com/posts/41833.html关于构造function adaptor的话题。
1 2 3 4 5 6 7 8 | template <typename operation>operation derivative_functor(operation f, typename operation::argument_type dx){ typedef typename operation::argument_type T; return [=](T x)->T { return (f(x + dx) - f(x)) / dx; };} |
这是前一篇文章最后构造的function adaptor。回忆一下,尽管我们不再需要在调用时指定lambda表达式的参数类型T,但是我们仍然需要指定operation的类型。从C++语法上讲,函数模板的调用应该是支持类型推导的,也就是说,如果调用derivative_functor的时候,没有指定operation的类型,C++编译时也会自动推导。可惜这种情况下自动推导的结果是错误的,以至于无法通过编译。
再看一下调用语句。
1 2 | typedef function<double (double)> operation;cout << derivative_functor<operation>(my_sqr_functor<double>(), 0.000001)(5) << endl; |
在这里我们给出的参数是my_sqr_functor<double>(),那么经过自动推导得到的operation类型就是my_sqr_functor<double>,尽管这个lambda表达式和my_sqr_functor<double>都分别兼容于类型function<double (double)>,但是它们两者之间没有继承关系,因此难以完成转换。
为了解决这个问题,我们就要避免出现这种不兼容的类型转换,只管的解决办法就是,令这个adaptor返回另一种类型的对象(而不是lambda表达式),这种对象的类型与operation指定的类型类似,并且同样可以像函数一样使用,兼容function<T (T)>类型。到这里我们必须要放弃lambda表达式,而用functor来模拟这个lambda表达式的行为了。
首先刚才说到,operation的类型和adaptor的返回类型有共性,下面让我们来构造这个共性的部分。
1 2 3 4 5 6 7 8 9 | template<typename Arg, typename Result>class my_unary_function{public: typedef Arg argument_type; typedef Result result_type;private: virtual Result operator()(Arg arg) = 0;}; |
这两者都可以当做一元函数来使用,并且我们用typedef定义了argument_type和result_type了,关于这个typedef的使用前一篇已经有一些说明。
1 2 3 4 5 6 7 8 9 | template<typename T>class my_sqr_functor_derived : public my_unary_function<T, T>{public: T operator()(T x) { return (x * x); }}; |
这个求平方的functor应该继承自这个my_unary_function,因为它“是”一个一元函数,这个继承关系会将父类的typedef一并继承下来。子类的T的实际类型会被代入父类my_unary_function的Arg和Result,成为自己的argument_type和result_type。
接下来就是重点的adaptor本身的改造了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | template <typename operation>class derivative_functor_derived : public my_unary_function<typename operation::argument_type, typename operation::result_type>{private: operation op; typename operation::argument_type dx;public: derivative_functor_derived(operation f, typename operation::argument_type x) : op(f), dx(x) {} typename operation::result_type operator()(typename operation::argument_type x) { return (op(x + dx) - op(x)) / dx; }}; |
首先这个adaptor现在是一个对象,它也“是”一个一元函数,因此同理,也继承自my_unary_function,并且指定恰当的模板参数。两个private对象,op和dx,就是先前lambda表达式中,从函数scope中传递下来的f和dx,我们在构造这个对象的时候,通过构造函数,将我们指定的op和dx保存到本对象的数据成员中,在括号运算符重载函数中,就可以使用op和dx了。至此,我们的adaptor是一个具有一元函数性质的对象,可以直接使用,而避免了不兼容类型的转换。
等一下!C++的语法不支持类模板的类型推导,这意味着我们调用这个构造函数的时候还是必须要指定的,像下面这样。
1 | cout << derivative_functor_derived<my_sqr_functor_derived<double> >(my_sqr_functor_derived<double>(), 0.000001)(5) << endl; |
我们刚才消除不兼容的类型转换,是为了省去模板参数的指定!别担心,注意到现在模板参数和传递的参数类型已经一致了吗?那现在我们只需要一个wrapper函数来帮助我们完成心愿。
1 2 3 4 5 | template <typename operation>derivative_functor_derived<operation> derivative_functor_derived_wrapper(operation f, typename operation::argument_type dx){ return derivative_functor_derived<operation>(f, dx);} |
这个函数所做的唯一的事情,就是调用了derivative_functor_derived的构造函数,不过因为这是一个函数模板,根据我们传递的f参数类型,就可以自动推导正确的operation类型了!
1 | cout << derivative_functor_derived_wrapper(my_sqr_functor_derived<double>(), 0.000001)(5) << endl; |
这里就是最终形式了。回想上一篇开头的STL Function Adaptor调用,看看是不是有些类似呢?
1 | cout << count_if(v.begin(), v.end(), bind2nd(less<int>(), 12)) << endl; |
我们的derivative_functor_derived_wrapper和STL函数模板bind2nd的行为完全一致。这就是STL Function Adaptor的实现原理。
至此,我们了解了STL Function Adaptor的设计思想和实现,并且能够使用functor来模拟一些lambda表达式的行为。
C++使用Lambda表达式做function adaptor
我们往往有许多现成的函数(或者是具有函数行为的对象),有些时候,我们希望通过改造这些函数来生成新的函数来为我们所用。
1 2 3 | int myArr[] = {1, 1, 2, 3, 5, 8, 13, 21};vector<int> v(myArr, myArr + sizeof(myArr) / sizeof(int));cout << count_if(v.begin(), v.end(), bind2nd(less<int>(), 12)) << endl; |
这段代码中less<int>()是临时functor对象,而bind2nd负责将这个接受两个参数比较他们大小的函数,将第二个参数绑定为12,改造成接受一个参数的functor,就可以被count_if所使用了。这段忙代码帮忙数出vector中小于12的项的数量。
我曾经在博客中写过利用Javascript闭包来实现的改造器。
1 2 3 4 5 6 7 8 9 | function derivative(f, dx) { return function (x) { return (f(x + dx) - f(x)) / dx; };} var result = derivative(function(x) { return x * x;}, 0.000001)(5); |
这个derivative是一个改造器,接受参数是一个函数f,返回其导函数。具体解释请参考http://deltamaster.is-programmer.com/posts/28768.html。
下面我们要用C++的Lambda表达式来实现类似功能。
现有一个非常简单的函数,求x的平方,和上面Javascript中的例子相同。
1 2 3 4 | double my_sqr(double x){ return (x * x);} |
下面我们写一个改造器。
1 2 3 4 5 6 | function<double (double)> derivative_simple(function<double (double)> f, double dx){ return [=](double x)->double { return (f(x + dx) - f(x)) / dx; };} |
这个改造器是一个函数,接受的第一个参数是一个函数指针,或者其他具有函数行为的对象,这种对象作为函数使用的时候,接受一个double类型的参数,返回double类型。这个改造器的返回类型和它的第一个参数类型相同。
在我们返回的Lambda表达式中,我们从改造器的scope把f和dx都以值传递方式传递进来。这个Lambda表达式根据输入参数x,求出这一点的导数值。
然后我们调用它,并接着直接调用其返回的Lambda表达式,得到x=5这一点的导数值。如我们所愿,我们看到了10(微积分还没有忘光吧)。
1 | cout << derivative_simple(my_sqr, 0.000001)(5) << endl; |
不过有一点不够理想的是,这个改造器的适用范围太狭窄了,如果我需要求导的函数接受的不是double类型的参数,而是Stone类型(假设这种神奇的Stone能进行数值计算),我们就要再写另一个差不多的改造器。这里你应该差不多想到了,我们可以用模板来实现。
1 2 3 4 5 6 7 | template <typename operation, typename T>operation derivative_any(operation f, T dx){ return [=](T x)->T { return (f(x + dx) - f(x)) / dx; };} |
大家可以比较这里的operation和T出现的位置,和上面的例子比较一下。然后我们调用它。
1 2 | typedef function<double (double)> operation;cout << derivative_any<operation, double>(my_sqr, 0.000001)(5) << endl; |
我们在调用之前用typedef做了一个类型声明,简化下面调用语句的书写。这次调用的效果还是一样的。但是如果将来真的要把Stone传进来,我们只要将operation指定为function<Stone (Stone)>,将T指定为Stone就可以了。
到这里就有一个小问题了,因为其实operation里的参数和返回类型,应该和T指定的类型总是相同的。按照上面的写法,淘气的程序猿完全可以指定不同类型,而造成不必要的错误。在编译时期发现错误还好,如果是发生了非预期的隐式类型转换而造成运行时错误,就很难发现了。
这样就要求我们能够在operation里携带一些类型信息,再将这个类型信息在改造器中取出,取代现在T的位置。不过一个普通的函数没有办法隐含这样的信息,于是我们需要把这个求平方的函数本身变成一个functor,以便保存额外的类型信息。
1 2 3 4 5 6 7 8 9 10 | template<typename T>class my_sqr_functor{public: typedef T argument_type; T operator()(T x) { return (x * x); }}; |
在这里我们用typedef来把类模板参数T定义为argument_type类型。想象一下,当这个模板被展开的时候,T被各种不同的类型替换,比如double,这个时候我们用typedef,将double在类的范围内定义为了argument_type。这样,我们在这个类外也总是能够通过对象的argument_type来获得当初指定给T的类型。
下面修改我们的改造器。
1 2 3 4 5 6 7 8 | template <typename operation>operation derivative_functor(operation f, typename operation::argument_type dx){ typedef typename operation::argument_type T; return [=](T x)->T { return (f(x + dx) - f(x)) / dx; };} |
改造器也相应升级了,我们在这里不需要再指定模板参数T了,而是用typename operation::argument_type来代替。下面再将它定义成T纯粹是为了书写方便。改造器的功能基本没有变化。然后我们调用它。
1 2 | typedef function<double (double)> operation;cout << derivative_functor<operation>(my_sqr_functor<double>(), 0.000001)(5) << endl; |
调用方法和上面稍有不同的,一方面我们不再能够指定那个模板参数T,另一方面my_sqr_functor<double>不再是一个函数,而是一个模板类,直接在后面加上括号调用其默认构造函数构造了一个临时对象,这种写法和最开头看到的less<int>()是同样的含义。
C++对于this指针使用placement new的隐患
我们知道使用placement new可以直接在现有的指针上构造对象,而不是先分配内存,再构造对象。这种技术经常被用在内存池管理中来优化内存管理效率。
有些情况下,我们希望能够让类的一个构造函数去调用另一个构造函数帮助我们完成工作,实现某种程度上的代码重用。比如下面这个例子。
1 2 3 4 5 6 7 8 9 10 11 | class Factory{private: Widget widget;public: Factory() { new (this) Factory("factory"); } Factory(const char *name) : widget(name) { /* something else useful */ }}; |
当Factory的默认构造函数被调用的时候,我们用Factory的默认名字“factory”去调用它自己的那个接受一个参数的构造函数,因为我们让placement new在自己(this)身上进行就地构造。不幸的是,这个例子里构造函数和析构函数没有配对调用的。
当调用者调用默认构造函数的时候,在函数体任何代码执行之前,所有Factory的子对象,也就是widget的默认构造函数Widget()被调用了。然后Factory决定再次调用自己带有一个参数的构造函数版本来完成构造,这个时候widget将再次被构造。最后当这个Factory的对象被析构时,相应的会调用一次widget的析构函数来销毁widget。
假设我们构造的这个Factory对象叫f。如果在Widget的默认构造函数中申请并占有资源,那么在f.widget没有被析构的情况下再次调用构造函数,那么之前f.widget所占有的资源就泄露了。于是,我们就必须在使用placement new之前,显式调用widget的析构函数来清理掉原来widget占有的资源。
1 2 3 4 5 6 7 8 9 10 11 12 | class Factory{private: Widget widget;public: Factory() { widget.~Widget(); // 新加了这一句 new (this) Factory("factory"); } Factory(const char *name) : widget(name) { /* something else useful */ }}; |
如果Factory有许多的成员,我们是不是要逐个调用这些成员的析构函数呢?这里高端大气的暴力方法是直接调用Factory自身的析构函数,那么Factory的析构函数会负责帮助我们析构所有的子对象并释放资源(反正我们接下来要一切从头来过,用另一个构造函数构造全新的Factory)。这里我们没有定义Factory的析构函数,那么就会使用编译器提供的默认版本,为我们调用所有子对象,也就是widget的析构函数。
1 2 3 4 5 6 7 8 9 10 11 12 | class Factory{private: Widget widget;public: Factory() { this->~Factory(); // 调用自身的析构函数 new (this) Factory("factory"); } Factory(const char *name) : widget(name) { /* something else useful */ }}; |
看起来有些丑陋,我们在自己的构造函数里,调用了自己的析构函数,然后又调用了另一个构造函数。如果要这样做,我们需要确保Factory的析构函数能够正确处理还没有被完全构造的对象,在这个简单的例子里,默认的析构函数已经足够处理这个问题,不过对于更加复杂的结构,我们还是需要认真考虑,对于这种没有完成构造的对象,析构函数能不能正确处理。
另一个问题,如果Factory有一个虚析构函数,那么Factory类的对象都需要一个虚函数表指针vptr来确保对象能够正确调用它的虚成员函数(包括析构函数)。一般实现在对象构造的一开始,任何基类或子对象的构造函数被调用之前,vptr已经有正确的值了,也是比较符合常理的做法。不过因为标准没有规定给vptr赋值的确切时机,所以并没有什么机制来保证我们一定能够运行正确的析构函数。
因此,为了实现借助其他构造函数完成构造的,我们写出来的代码不太安全。就这个简单的例子有以下方法可以取代这种做法。
- 把“factory”作为第二个构造函数name参数的默认值,直接去掉第一个构造函数即可。
- 把构造逻辑的公共部分抽象出来成为一个private成员函数来专门对未完成初始化对象的初始化动作(不要写成虚函数)。
所以,尽量避免对this指针使用placement new,我们一般能够找到更好的设计来解决这样的需求。如果一定需要,那么务必要审慎考虑上面所提到的这些因素。
在C++中使用成员函数指针
函数指针的语法相对比较复杂,成员函数指针则在此基础上进一步引入了类作用域限定。让我们来了解一下成员函数指针的写法。
首先回顾一下函数指针的使用方法。有这样一个函数:
1 2 3 4 | double func(double x){ return 3.14 * x;} |
我们这样声明函数指针,并且进行调用:
1 2 3 | double (*pfunc)(double x);pfunc = &func;cout << (*pfunc)(1.1) << endl; |
指针的声明包括返回类型、指针名和函数的参数表,对于一个强类型的编译型语言,这些要素都必不可少。由于运算符优先级的规定,还要特别注意在适当的位置加上括号。
对于成员函数指针,就是增加了一个作用域限定。
首先有一个类A,包含几个类型相同的函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | class A{public: void f1(int x) { cout << "f1:" << x << endl; } void f2(int x) { cout << "f2:" << x << endl; } void f3(int x) { cout << "f3:" << x << endl; }}; |
然后类B的对象会调用类A的对象的成员函数,然而具体调用哪一个还不知道,我们通过指针的方式来实现,在运行时将指针指向一个类型兼容的成员函数。
1 2 3 4 5 6 7 8 9 10 11 | class B{public: void (A::*pf) (int x); //注意作用域运算符和*的次序,括号不能省略 void callF(int x) { A a; (a.*pf)(x); }}; |
我们在外部实例化B的对象,然后为B的成员函数指针赋值,确定将要调用的是哪一个函数。
1 2 3 4 | cout << "Hello world!" << endl;B b;b.pf = &A::f2;b.callF(5); |
C++中的函数对象与Lambda表达式
函数对象是C++中以参数形式传递函数的一个很好的方法,我们将函数包装成类,并且利用()运算符重载实现。
1 2 3 4 5 6 | typedef class hello {public: void operator()(double x) { cout << x << endl; }} hello; |
这时候hello是一个类,我们可以实例化一个对象hello h;,然后通过h(3.14)的方式来调用这个类的成员函数,如果某个函数需要这个函数作为回调函数,则可以将这个hello类的对象传入即可。
因为这是一个类的定义,因此我们完全可以在其中定义一些包含额外信息的成员和一些构造函数,让这个函数对象可以做更多不同的可定制的任务,最终的行为实际上只是调用了这个()运算符重载函数。这种做法比C++函数指针要容易理解得多,也不容易写错。
而Lambda表达式则是C++中的新语法,实现了许多程序员渴望的部分闭包特性。C++中Lambda表达式可以被视为一种匿名函数,这样,对于一些非常短,而且不太可能被其他地方的复用的小函数,可以通过Lambda表达式提高代码的可读性。
在Lambda表达式中对于变量生命期的控制还是与完全支持闭包的JavaScript非常不同,总而言之,C++对于变量声明期的控制在新标准中完全向前兼容,也就是局部变量一定在退出代码块时被销毁,而不是观察其是否被引用。因此,尽管C++的Lambda表达式中允许引用其代码上下文中的值,但是实际上并不能够保证引用的对象一定没有被销毁。
Lambda表达式对于上下文变量的引用有值传递和引用传递两种方式,实际上,无论是哪种方式,在产生Lambda表达式对象时,这些上下文值就已经从属于Lambda表达式对象了,也就是说,代码运行至定义Lambda表达式处时,通过值传递方式访问的上下文变量值已经被写入Lambda表达式的栈中,而引用方式传递的上下文变量地址被写入Lambda表达式的栈中。因此,调用Lambda表达式时得到的上下文变量值就是定义Lambda表达式时这些变量的值,而引用的上下文变量,如果已经被销毁,则会出现运行时异常。
Lambda表达式的基本语法是:
[上下文变量说明](Lambda表达式参数表) -> 返回类型 { 语句块 }
上下文变量说明部分就是说明对于上下文变量的引用方式,=表示值传递,&表示引用传递,例如,&s就表示s变量采用引用传递,不同的说明项之间用逗号分隔,可以为空,但是方括号不能够省略。第一项可以是单独的一个=或者&,表示,所有上下文变量若无特殊说明一律采用值传递/引用传递,什么都不写默认为值传递。
Lambda表达式和TR1标准对应的function<返回类型 (参数表)>对象是可以互相类型转换的,这样,我们也可以将Lambda表达式作为参数进行传递,也可以作为返回值返回。
下面看一个Lambda表达式各种使用方法的完整例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | // compile with: /EHsc#include <iostream>#include <string>#include <functional> //这是TR1的头文件,定义了function类模板using namespace std;typedef class hello {public: void operator()(double x) { cout << x << endl; }} hello; //函数对象的定义,也是非常常用的回调函数实现方法void callhello(string s, hello func) { cout << s; func(3.14);} //一个普通的函数void callhello(string s, const function<void (double x)>& func) { cout << s; func(3.14);} //这个函数会接受一个字符串和一个Lambda表达式作为参数void callhello(string s, double d) { [=] (double x) { cout << s << x << endl; }(d);} //这个函数体内定义了一个Lambda表达式并立即调用function<void (double x)> returnLambda(string s) { cout << s << endl; function<void (double x)> f = ([=/*这里必须使用值传递,因为s变量在returnLambda返回后就被销毁*/] (double x) { cout << s << x << endl; }); s = "changed"; //这里对s的修改Lambda表达式是无法感知的,调用这句语句前s在Lambda表达式中的值已经确定了 return f;} //这个函数接受了一个值传递的字符串变量s,我们将Lambda表达式作为返回值返回function<void (double x)> returnLambda2(string& s) { cout << s << endl; function<void (double x)> f = ([&s/*这里可以使用引用传递,因为s是引用方式传入的,不随函数返回而消亡*/] (double x) { cout << s << x << endl; }); s = "changed"; //这里对s的修改Lambda表达式是可以感知的,因为s以引用方式参与到Lambda表达式上下文中 return f;} //这个函数接受了一个引用传递的字符串变量s,将Lambda表达式作为返回值返回int main() { hello h; callhello("hello:", h); //用函数对象的方式实现功能 callhello("hello lambda:", -3.14); //这个函数体内定义了一个Lambda表达式并立即调用 int temp = 6; callhello("hello lambda2:", [&] (double x) -> void { cout << x << endl; cout << temp++ << endl; }); //这个函数会接受一个字符串和一个Lambda表达式作为参数 cout << temp << endl; function<void (double x)> f = returnLambda("lambda string"); //这个函数接受了一个值传递的字符串变量s,我们将Lambda表达式作为返回值返回 f(3.3); string lambdastring2 = "lambda string2"; //这个变量在main函数返回时才被销毁 f = returnLambda2(lambdastring2); //这个函数接受了一个引用传递的字符串变量s,将Lambda表达式作为返回值返回 f(6.6); system("pause");} |
C++中的typedef语法简介
根据名字也可以猜测到,typedef这种语法可以用于定义类型,如果某种类型的名称很长,或者未类型增加语义,那么我们就可以考虑使用typedef。看看最简单的例子:
1 | typedef int INT; |
上面的一行代码就表示INT也能代表int,这条定义可以在Windows头文件中找到。有什么意义呢?这是一种跨平台编译的考虑,看一下另一个Windows头文件中的例子:
1 2 3 4 5 | #ifndef UNICODE typedef char TCHAR; #else typede wchar_t TCHAR; #endif |
如果当前环境支持Unicode,那么TCHAR就会等价于wchar_t宽字符类型,否则TCHAR等价于char类型,那么程序员就可以借助TCHAR来隐藏具体的编译环境。
此外,typedef还可以增强语义,在Windows中所有的句柄本质都是void*类型,而为了增强语义,产生了HWND、HMENU、HBRUSH等不同的类型,让程序可读性增强。
大多数情况下,typedef是可以用#define来进行替换的,例如:
1 | #define INT int |
不过问题在于,#define只是进行了简单的字符替换,在编译前就被预编译器处理了,而typedef的处理则是编译器行为,因此使用typedef,编译器将能够视INT为一个类型,而不是其他东西。下面还有一个用#define容易引起混淆的例子。
1 2 3 4 5 | #define pINT int*;typedef int *pINT2;pINT a, b;pINT2 c, d; |
一般而言,我们通过类型定义,是希望将pINT定义成一种类型,那么用这种类型进行定义得到的变量,都应该是这种类型。而如果使用#define,那么看起来我们用pINT定义了a和b,实际上只有a是int*,而b只是int。使用typedef很好地避免了这个问题,c和d都是int*类型,这样不至于产生混乱的语义。
另外,因为typedef不是预编译指令,而被当作语句执行,因此也是有作用域的,typedef的作用域和一般变量相同。冲突的定义会进行覆盖,较晚执行的typedef会覆盖较早执行的typedef。
最后,typedef还可以用来定义类、结构体、联合体、数组,甚至是函数类型,下面有一个比较全面的代码例子,可以参考注释理解其中的含义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | #include <iostream>using namespace std;typedef int* _int, _int2; //_int是int*类型,而_int2是int类型typedef int INT; //INT是int类型typedef _int *INT2, *INT3; //INT2和INT3都是*_int类型,也就是**int类型typedef void (*funcptr)(double); //funcptr是一个函数指针类型,指向返回值为void,接受一个double类型参数的函数typedef union { char c; int i; bool b;} Foo; //Foo是一个联合体typedef class TestClass { int a, b, c;public: TestClass(int a, int b, int c) : a(a), b(b), c(c) { }} TESTCLASS; //TESTCLASS就是TestClass类void hello(double x) { //funcptr可以指向这个函数 cout << x << endl;}int main() { INT a = 6; _int2 e = 7; _int c = &a; INT2 b = &c; INT3 d = &c; cout << a << e << *c << **b << **d << endl; funcptr p = hello; p(3.333); cout << p << endl; Foo foo; foo.i = 65; cout << foo.b << foo.c << foo.i << endl; TESTCLASS tc(1, 2, 3); system("pause"); return 0;} |
C++断言与静态断言
断言是很早之前就有的东西了,只需要引入cassert头文件即可使用。往往assert被用于检查不可能发生的行为,来确保开发者在调试阶段尽早发现“不可能”事件真的发生了,如果真的发生了,那么就表示代码的逻辑存在问题。最好的一点就是,断言只在Debug中生效,因此对于Release版本是没有效率上的影响的。
1 2 3 4 5 6 7 8 9 10 | #include <iostream>#include <cassert>using namespace std;int main() { int i = 22; assert(i != 22); system("pause"); return 0;} |
上面的代码就表示,你确认在这里i一定不会等于22,如果事实上真的是22,那么程序就会无情地被abort,并报告出现问题的源文件和行号(使用了魔法常量__FILE__和__LINE__),有助于及时定位问题。
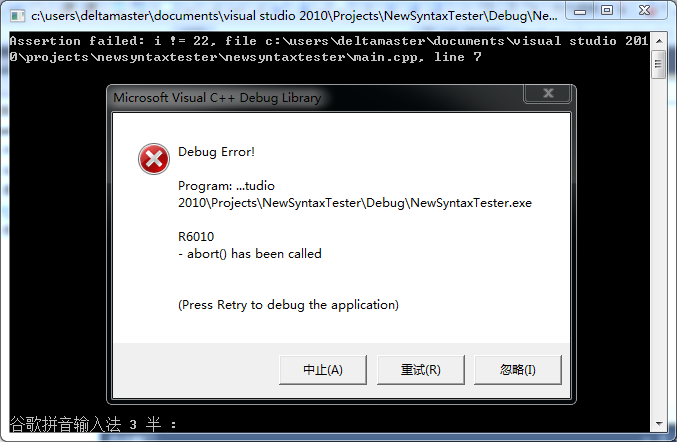
断言有一个问题,就是一定会abort,强制整个程序退出而导致调试也无法继续进行,就像上图这样,出现问题后,我们知道了出现问题的行号,但是我们需要手动在该行的上面设置断点,重新开始调试才能够检查到发生问题时各个变量的状态。而且,有时问题不是那么容易重现,于是就可能出现没法重现错误再检查状态的问题。
所以,我们可以自己写一个类似的宏来解决这个问题,我们希望在违反断言时触发断点陷阱门中断而不是调用abort,这样,在违反断言时程序会暂停下来,等待程序员来检查当前的状态有何异常。
下面是一个Visual C++中的实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 | #include <iostream>#include <cassert>using namespace std;#define _ASSERT(x) if (!(x)) __asm {int 3};int main() { int i = 22; //assert(i != 22); _ASSERT(i != 22); system("pause"); return 0;} |
上面定义了一个宏,名字当然可以自己取,实际上做的一件事就是检查断言,然后如果断言结果为false(0),那么就调用内联汇编指令int 3陷入调试中断。
在2011年的C++标准中出现了静态断言(static_assert)的语法,所谓静态断言,就是在编译时就能够进行检查的断言,static_assert是C++的标准语法,不需要引用头文件。静态断言的另一个好处是,可以自定义违反断言时的编译错误信息。
1 2 3 4 5 6 7 8 9 | #include <iostream>using namespace std;int main() { const int i = 22; static_assert(i != 22, "i equals to 22"); system("pause"); return 0;} |
这个代码,将无法通过编译,因为i的值违反了静态断言。

静态断言的限制是,断言本身必须是常量表达式,如果这样的i不是常量,静态断言是不符合语法的。